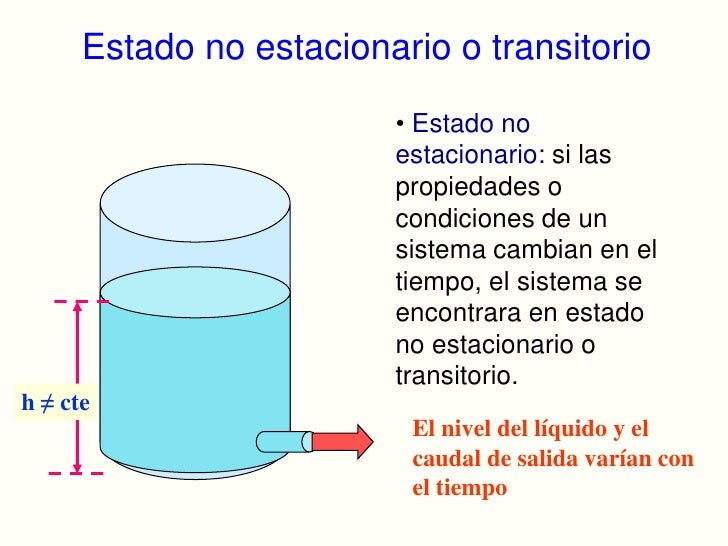
Estado estable
Una variable está en estado estacionario (estable) si su valores período es el mismo durante el período de tiempo que estamos considerando.Una simulación está en estado estacionario si todas sus colas lo están. El estado estacionario es alcanzado luego de un período de tiempo llamado período transitorio inicial (run-in).
Reloj de Simulación:
Es el contador de tiempo de la simulación, y su función consiste en responder preguntas tales como cuánto tiempo se ha utilizado el modelo de la simulación, y cuanto tiempo en total se requiere que dure esta última.Existen dos tipos de reloj de simulación: el reloj de simulación absoluto, quedarte del cero y termina en un tiempo total disimulación definido, el reloj de simulación relativo, que solo consiste en el lapso de tiempo que transcurre entre dos eventos.
Ejemplo
El tiempo de proceso de una pieza es relativo, mientras que el tiempo absoluto seria el global: desde que la pieza entro a ser procesada hasta el momento que terminó su proceso.
Estado estacionario, Condiciones y Sesgo inicial Para obtener resultados confiables:
Durante todo el tiempo en que se toman las medidas (cuando se registran los datos de la simulación) el sistema debe estar en estado estacionario. Condiciones iniciales: son los valores iniciales de los parámetros para una simulación en estado estacionario. Las condiciones iniciales determinan un sesgo inicial que influye en el tiempo que lleva alcanzar la estabilidad, en los resultados y en las estimaciones calculadas. Este sesgo se puede anular realizando simulaciones durante un período de tiempo muy largo.
Cómo obtener resultados confiables Existen 3 maneras:
1. Comenzar en estado estacionario con información del "sistema real”. Cantidad y tipo de entidades en actividad y en colas, organizadas en el calendario según información anterior y de acuerdo a sus distribuciones
2. La simulación se corre hasta alcanzar estado estacionario y se toma
“ese” estado del sistema como punto de partida para las siguientes
corridas.
3. Se corre la simulación desde el “sistema vacío” hasta el “estado estable”, allí se comienzan a recolectar datos. Se desprecian las medidas del período “run-in”.
El tercer método es el más “seguro”. En los dos primeros se corre el riesgo de
obtener datos sesgados; cuando se alcanza el estado estacionario puede variar dependiendo a veces de los distintos valores de las variables de decisión.
¿Qué es una réplica?
Copia exacta o muy similar. Función de las réplicas las réplicas; se presentan con la finalidad de obtener estadísticas de intervalo que nos den una mejor ubicación del verdadero valor de la variable bajo los diferentes escenarios que se presentan al modificar los números pseudo aleatorios en cada oportunidad. Disminuir el error de la simulación Importancia de las réplicas en simulación. De esta manera se obtiene una relación entre el número de réplicas y la precisión de la estimación, de manera que entre más replicas se tengas más preciso será el modelo.
Tipos de réplicas Muestreo antitético:
es inducir una correlación negativa éntrelos elementos correspondientes en las series de números aleatorios utilizados para generar variaciones de entrada en réplicas diferentes.
Corridas comunes:
El objetivo principal es iniciar nuevas corridas de simulación utilizando siempre los datos almacenados; de esta forma, el uso de las corridas comunes afecta a todas las alternativas de igual forma. Se debe aplicar cuando el problema consiste en la comparación de dos o más alternativas.
Muestreo Clasificado:
Esta técnica se apoya en un resultado parcial de una corrida, clasificándolo como interesante o no interesante, en caso de ser interesante se continúa con la corrida en caso contrario se detiene la corrida.
Variaciones de control:
Este método utiliza aproximaciones de modelos analíticos para reducir la varianza. Muestreo estratificado: En esta técnica la función de distribución se divide en varias partes, lo más homogéneas posibles que se resuelven o ejecutan por separado; los resultados obtenidos se combinan para lograr una sola estimación del parámetro a analizar.
Muestreo sesgado:
Consiste en distorsionar las probabilidades físicas del sistema real, de tal forma que los eventos de interés ocurran más frecuentemente. Los resultados obtenidos presentarán también una distorsión que debe corregirse mediante factores probabilísticos de ajuste.
¿Cómo estimar en simulación el número de réplicas Replicas en ProModel? Para estimar el número de corridas necesarias debe realizarse un número de corridas de manera preliminar, por ejemplo, de 30 a 50. Esto se hace a través del menú de ProModel SIMULATION/OPTIONS lo que dará lugar a que se despliegue un cuadro de diálogo en el cual se agregará el número de corridas elegido en el campo "number of replications". Ahora bien, antes de emplear la fórmula para estimar el número de corridas debes elegir la variable de respuesta sobre la cual realizarás este análisis. Puede ser el contenido de alguna fila (average content), o el total de piezas producidas (current value), el tiempo en el sistema (averagedminutes in system), la utilización de máquinas o estaciones de trabajo (%utilization), etc. Todo depende del objetivo del estudio que se está realizando y enfunción de lo que se desea mejorar. A partir de que se elige la(s) variable(s) dereferencia para el análisis se recabará del reporte general ponderado la media y desviación estándar obtenida en esa variable en particular, los cuales serán
respectivamente los valores de X (la media) y σ
(la desviación estándar) a sustituir en la siguiente fórmula: Si el número de corridas obtenido de la fórmula se cubrió con el número de corridas preliminares significa que ya no es necesario hacer más corridas; pero si el número de corridas calculado es superior al que se consideró de manera preliminar entonces deberán realizarse las corridas que sean necesarias.
PRUEBA DE CORRIDAS ARRIBA Y ABAJO
Si tenemos una secuencia de números de tal manera que a cada uno de los números siga otro mayor la secuencia dada será ascendente (arriba). Si cada número va seguido por otro menor, la secuencia será descendente (abajo)PROPIEDADES Las dos propiedades más importantes esperadas en los números aleatorios son uniformidad e independencia. La prueba de uniformidad puede ser realizada usando las pruebas de ajuste de bondad disponibles Los números pueden estar uniformemente distribuidos y aun no ser independientes uno del otro. Por ejemplo, una secuencia de números monótona mente se incrementa dentro del rango de cero a uno esta uniformemente distribuida si la cantidad_réplica, corrida, estado transitorio, estado estable, condiciones iniciales, reloj de la simulación_ incrementa es constante para todos. (0, 0.1, 0.2, 0.3, ......,0.9)
PRUEBA DE CORRIDAS
Una prueba de Corridas es un método que nos ayuda a evaluar el carácter de aleatoriedad de una secuencia de números estadística mente independientes y números uniformemente distribuidos. Es decir, dado una serie de números determinar si son o no aleatorios.
PRUEBAS DE CORRIDA ARRIBA Y ABAJO
Ahora procedemos a calcular el total de corridas que resulta de la suma de suma de corrida ascendente con la descendente.